OneClass SVM:異常檢測任務 (Anomaly Detection) 的算法理解與實踐
前言
因緣際會看了一篇 2016 KDD ( Knowledge Discovery and Data Mining Conference ) 的 Paper — Catch Me If You Can: Detecting Pickpocket Suspects from Large-scale Transit Records,其要解決的問題為在交通系統上能辨識出潛在小偷。
在數據方面,他們主要使用了北京公交一卡通數據進行探勘,並花了相當大的工作在特徵構建以及有趣的分析(例如小偷會在特定區域滯留、定義何為詭異行為、地圖劃分區域功能等);在算法方面,其最大的難點在於,行為複雜的乘客與小偷的 pattern 都屬於異常檢測算法當中在決策邊界以外的稀疏點,因此本篇使用了兩階段模型,第一階段是異常檢測,即為本篇要介紹的 OneClass SVM,過濾出正常與異常行為的乘客,第二階段是 SVM 的分類模型,去改善異常當中被誤判為小偷的正常乘客分不好的情況。
然而,這類的問題存在重視高 Recall,忍受低 Precision 的情形,這篇論文的 Recall = 0.927, Precision = 0.071,也就是說寧可錯抓,也不要漏放任何一位可疑的小偷。若對此篇論文有興趣,可以參考文末的 Sharing Slides。
一、算法介紹
Anomaly Detection 是什麼?
又稱為異常偵測,要從茫茫數據中找到那些「長的不一樣」的數據,如下圖,理想中我們可以找到一個框住大部分正常樣本的 decision boarder,而在邊界外的數據點(藍點)即視為異常。

但實際情況下數據都沒有標籤( label ),因此很難定義「具有代表性的正常」區域。異常偵測主要的挑戰如下:正常與異常行為之間的界限往往並不明確、不同的應用領域對異常的確切定義不同、數據可能含有噪聲、異常行為的數據較難以蒐集(樣本量極少、在訓練時會有嚴重 imbalanced data 的問題) 以及正常行為並不是一成不變,會有不斷發展變化的 pattern。
因此像是前言提到的的抓小偷、欺詐偵測、元件的損壞檢測等問題都能參考 Anomaly Detection 做為解法。異常偵測的算法非常多元,有興趣可以看這篇:深入機器學習系列 — — 異常檢測 ( Anomaly Detection )。

接下來,我們開始介紹本次的主角:OneClass SVM 算法(在 Catch Me If You Can 當中篩選行為異常的乘客)。
OneClass SVM 簡介
OneClass SVM 是一個 unsupervised 的算法,顧名思義訓練數據只有一個分類。透過這些正常樣本的特徵去學習一個決策邊界,再透過這個邊界去判別新的資料點是否與訓練數據類似,超出邊界即視為異常。
算法中使用到 RBF ( Gaussian Radial Basis Function ) 的 Kernel 函數,是 SVM 分類算法中最為常用的 Kernel 函數,將特徵投影到高維空間(右下圖), maximize 高維空間與原點的距離,得到與原點距離最大的超平面。關於 RBF 如何經由泰勒級數推導得出 Kernel 函數,可以參考:機器學習: Kernel 函數。

Kernel函數:只要對所有的資料,有一個函數可以滿足 k(x,y)=⟨φ(x),φ(y)⟩ 這個 k(x,y) 就是一個 Kernel 函數,⟨a, b⟩ 表示向量 a 和 b 做內積。
二、scikit — learn實踐
透過 scikit learn 我們可以簡單、方便的調用,以下使用 OneClass SVM 範例程式碼 體會一下OneClass SVM 針對偵測異常的邊界到底是怎麼決定的。
第一步:數據生成
- X_train: 產生兩組大小為 ( 100, 2 ) 並且服從常態分佈 𝑁( 𝜇, 𝜎² ) 的隨機數:X ~ N( 2, 0.3² ) 與 X~ N( -2, 0.3² ) ;接著將兩組隨機數透過
np.r_[]左右拼接。 - X_test: 產生兩組大小為 ( 20, 2 ) 且服從常態分佈的隨機數,常態分佈的𝜇 與 𝜎 以及拼接方法同上。
- X_outliers: 產生大小為 ( 20, 2 ) 介於 [-4, 4) 的隨機數。
# 訓練數據(正常)
X = 0.3 * np.random.randn(100, 2) # size=(100,2)
X_train = np.r_[X + 2, X - 2] # size=(200,2)# 測試數據(正常)
X = 0.3 * np.random.randn(20, 2)
X_test = np.r_[X + 2, X - 2]# 測試數據(異常)
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
第二步:模型訓練
在 scikit-learn 提供 OneClass SVM 的說明頁面有提到:預測返回的 y 值為 1 代表正常 (inlier),返回值為 -1 代表異常 ( outlier ),與分類模型當中對應的 0 為正常、 1 為異常有所不同。前面有提到我們是透過 unsupervised learning 的方式極小化正常樣本與邊界的距離,因此邊界如何定義就是 nu 這個參數(介於 0~1的比率)在控制的事情。舉例:nu =0.1,代表了:正常樣本卻誤判為異常的最多不超過 10% (以本範例來說,200 個樣本當中,被判為異常的要不超過 20 個 );至少要有正常樣本的 10%(也就是 20 個)作為衡量與邊界 margin 的 support vectors。
nu: An upper bound on the fraction of training errors and a lower bound of the fraction of support vectors. Should be in the interval (0, 1]. By default 0.5 will be taken.
而 gamma 代表了 RBF Kernel 將樣本投影到高維空間的縮放比例,gamma 值設定的越小代表樣本在高維空間的越分散,即 𝜎 越大,在訓練時的作用可能會造成準確率較低,但預測未知樣本的泛化能力強;反之 gamma 值設定的越大,樣本在高維空間會擠在一起,所獲得的 support vectors 就會較少,訓練時準確率較高,但預測未知的泛化能力弱。
# fit the model (nu=0.1)
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
n_error_outliers = y_pred_outliers[y_pred_outliers == 1].size
透過模型預測後,我們可以得到 n_error_train 、 n_error_test ,代表了實際正常誤判為異常的個數,在分類模型當中類似於 false positive 的概念 ( 分類模型中實際為 0,誤判為 1 ); n_error_outliers 代表實際為異常誤判正常的個數,也就是其實是 outlier 但落在邊界內部裡,類似於 false negative (分類模型中實際為 1 ,誤判為 0 )。
第三步:視覺化
上面提到很多次的正常與異常樣本之間的決策邊界到底長什麼樣子呢?紅色邊界內為正常樣本(白色為正常的訓練數據、紫色為正常的測試數據),而在紅色邊界以外的即判定為異常(黃色為異常的測試數據)。
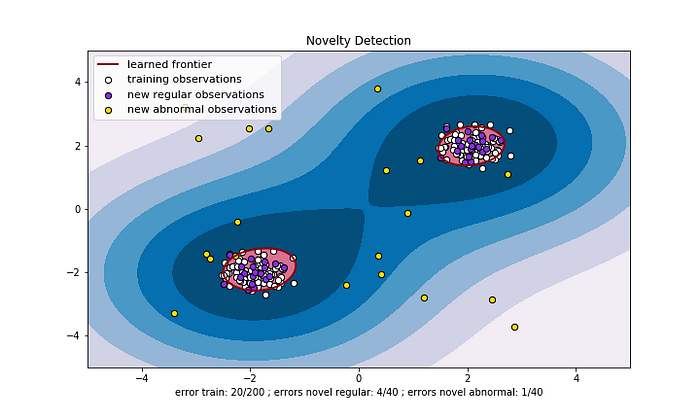
主要比較 nu=0.1(上圖)與 nu=0.5(下圖)的差異:可以看到 OneClass SVM 學習到的決策邊界在 nu 值越小的時候,紅色邊界所包含的範圍較大、也包含較多的正常樣本,但同時也有可能會發生誤把異常視為正常的缺點。
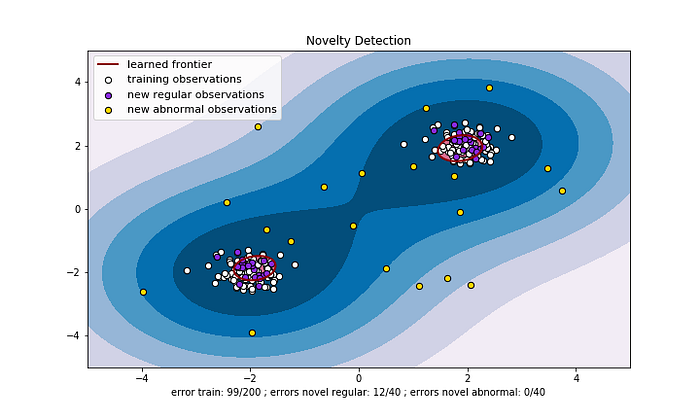
因此,如果不希望異常誤判為正常(意即想要擁有較小的 false negative),則可以將紅色邊界內縮, nu 值設為大一些(default 值是設為 0.5)。
關於視覺化 part 會使用到的用法
1. np.meshgrid(xx, yy): 初始化生成網格點的橫縱座標矩陣
# 生成網格點
xx, yy = np.meshgrid(np.linspace(-5, 5, 500), np.linspace(-5, 5, 500))# result: xx
array([[-5. , -4.97995992, -4.95991984, ..., 4.95991984,
4.97995992, 5. ],
[-5. , -4.97995992, -4.95991984, ..., 4.95991984,
4.97995992, 5. ],
[-5. , -4.97995992, -4.95991984, ..., 4.95991984,
4.97995992, 5. ],
...,
[-5. , -4.97995992, -4.95991984, ..., 4.95991984,
4.97995992, 5. ],
[-5. , -4.97995992, -4.95991984, ..., 4.95991984,
4.97995992, 5. ],
[-5. , -4.97995992, -4.95991984, ..., 4.95991984,
4.97995992, 5. ]])# result: yy
array([[-5. , -5. , -5. , ..., -5. ,
-5. , -5. ],
[-4.97995992, -4.97995992, -4.97995992, ..., -4.97995992,
-4.97995992, -4.97995992],
[-4.95991984, -4.95991984, -4.95991984, ..., -4.95991984,
-4.95991984, -4.95991984],
...,
[ 4.95991984, 4.95991984, 4.95991984, ..., 4.95991984,
4.95991984, 4.95991984],
[ 4.97995992, 4.97995992, 4.97995992, ..., 4.97995992,
4.97995992, 4.97995992],
[ 5. , 5. , 5. , ..., 5. ,
5. , 5. ]])
2. clf.decision_function(): 呈現 OneClass SVM 所學習到的邊界(樣本經過RBF Kernel 函數的轉換,邊界的本質是一個超平面,投影到二維平面看起來像是一個圈圈)
3. np.r_[arr1, arr2]: 支援 arr1, arr2 水平合併
# arr1與 arr2 長度不一樣仍然可以合併
arr1 = [1,1,1]
arr2 = [2,2,2]
arr3 = [3,3,3,3]print(np.r_[arr1, arr2])
print(np.r_[arr1, arr3])# result
[1,1,1,2,2,2]
[1,1,1,3,3,3,3]
4. np.c_[arr1, arr2]: 支援 arr1, arr2 垂直合併
# arr1與 arr2 長度需要一樣才可合併,否則會報 error
arr1 = [1,1,1]
arr2 = [2,2,2]
print(np.r_[arr1, arr2])# result
[[1 2]
[1 2]
[1 2]]
本篇實踐 scikit — learn OneClass SVM 完整程式碼:
參考來源
- Catch Me If You Can: Detecting Pickpocket Suspects from Large-Scale Transit Records
- Scikit Learn — OneClass SVM
- Scikit Learn — Novelty and Outlier Detection
- 深入機器學習系列 — — 異常檢測(Anomaly Detection)
- OneClass SVM介紹
- 機器學習: Kernel 函數
- Microsoft Azure: One-Class Support Vector Machine
- SVM的兩個參數C 和gamma
如果這篇文章有幫助到你,可以幫我在下方綠色的拍手圖示按5下,只要登入Google或FB,不需任何花費就能【免費支持】youmgmi 繼續創作。
